
Introduction
This is part 3 of the CTRT series. You can read the complete series here:
- Part 1: Rendering a Sphere
- Part 2: BRDFs and Shadows
- Part 3: Phong and Reflections
Last time, we discussed a series of optimisations for the compile-time ray tracer we designed in part 1 along with a way of implementing BRDFs and shadows. In today’s travel, we will continue developing the ray tracer by adding specular shading and reflections. We will also use this as an excuse to discuss how to parallelise the ray tracer. With this in mind, let’s get started by adding specular shading.
Note
At the top of each section, you will find links to all the files that are discussed there in case you want to read the code along with the explanations. The entire source code for this post can be seen here
Ooh… Shiny
The ultimate goal in terms of shading is to have perfect mirror reflections. To do that, we first need to implement specular shading, which we will handle by implementing the Phong specular model. We begin by creating a new BRDF which will be in charge of the specular highlights. The general equation for describing them is as follows:
$$ k_s \cdot c_s \cdot (\mathbf{r} \cdot \mathbf{\omega_o})^{e} $$Where $k_s$ is the specular reflection coefficient, $c_s$ is the specular colour, $\mathbf{r}$ is the direction of the reflected light, $\mathbf{\omega_o}$ is the viewing direction, and $e$ is the specular exponent. Under normal circumstances, this formula would be implemented like this:
| |
The problem here is that we need std::pow, which is part of the maths
functions of the STL… and therefore not constexpr. Since we’re mostly
dealing with integral exponents, we can write a simplified version of the pow
function as follows:
| |
Notice that we’re not going to make it recursive since due to the optimisations
we previously discussed (particularly simplifying the call-stack). Now that we
have our pow function, we can implement the BRDF as follows:
| |
The Phong material is conformed by two BRDFs: the Lambertian BRDF which will
handle diffuse shading and the specular BRDF we just wrote. Since we still need
to handle shadows, they’re also going to be included in the implementation, and
so we end up with this:
| |
Perfect! Let’s setup a new scene and try it out. After 15 minutes, we end up with the following:

Now that we have specular highlights, lets implement reflections.
Mirror, Mirror, on the Wall…
Since we’re adding a new material, we first have to add a new BRDF. A perfect reflection BRDF is a bit different from the others we’ve written so far, mainly because we are not interested in evaluating the BRDF function. Indeed, in a perfect mirror, the colour of the surface is not determined by the surface, but rather by the colour of the surfaces that are reflected on it and the base colour of the reflective surface itself. To fully understand this, imagine a perfect mirror. The colours on the mirror are entirely dependent on whatever is being reflected on it. Now suppose we tint the mirror with a colour (say red). The resulting colour on the surface of the mirror is composed of the red tint and whatever is being reflected.
What we’re actually interested in is not the evaluation of the BRDF itself, but
rather the direction in which the rays are going to be reflected and the base
colour of the mirror (if any). Therefore, we’re going to be adding a new
function to our BRDF base class:
| |
Notice that due to the usage of CRTP, every time we add a function to the base
class, we must implement it in all the derived classes (otherwise the
compiler will issue a warning/error about infinite recursion on the base class
since it ultimately calls itself). For all of our existing BRDFs, sample_fn
will return a default tuple. Now that this is done, we can create a new BRDF:
| |
The naming is due to the fact that the previous BRDF that we created is used to create glossy specular (so not perfect) reflection, whereas this one will generate pure specular reflections. Now that this is set, we need to discuss the material itself.
In general, reflections in ray tracing are handled through recursive function calls. A very simple version of this would involve something like this:
| |
This is fine if we aren’t dealing with the restrictions of constexpr. Since we
are, then we have to be a bit more careful. The recursive call still has to
happen, but the question now is where. Looking through our current setup, it
turns out that it is a lot easier to have the materials themselves be recursive,
since those are the only ones that deal with the colour computations. So, we
would be changing the shade function as follows:
| |
In order to do this, we’re going to need to pass the container of shapes down to
the shade function. This is simple enough, all we have to do is tack on
another template parameter to the base shade class and propagate the changes.
The new base shade function ends up looking like this:
| |
Now that we have the base ready to go, let’s create the new reflective material:
| |
There’s a couple of things to unpack here, so let’s go one at a time. Since
reflections are recursive process, we need a base case in order to not have
infinite recursion. To handle this, we’re going to add two now elements to the
ShadeRec structure: a counter and a maximum reflection depth. Since the
counter is always initialised to 0, we just have to make sure we copy (and
increase) the current counter whenever we pass it down to the next material to
shade. The base case is handled first: if we have exceeded the reflection limit,
just return black.
The next bit is the recursion part of the function. Note that we have
essentially copied over the code from the main render function. This is on
purpose since the code is essentially the same, the only major difference is
that we are accumulating the colour from the reflected materials in L.
Finally, the “base” colour of the mirror is computed using Phong (this is why we
needed to implement it first) so that we can still have specular reflections on
it.
We now have a reflective material, so lets test it out. We can take the previous scene and replace a couple of spheres with reflective materials to get this:

Not bad! Our ray tracer is now pretty capable, but it would be nice if we could somehow make it faster.
How do we Parallelise the Compiler?
Before we begin our discussion, let’s first take note of our current render times:
| Scene | Time |
|---|---|
| Just Background | 21m 6s |
| Red Sphere | 11m 43s |
| Shadows | 42m |
| Phong | 15m 33s |
| Reflections | 17m 31s |
We have previously discussed several optimisations we could make in our code to increase the performance of the renderer. These improvements led to the times we noted above, but there must be more that we can do. So the question is what?
Let’s forget about the fact that we’re dealing with constexpr functions for a
moment and let’s think about what we could do if this were a normal ray tracer.
Looking through the algorithm, we can quickly realise that it is trivially
parallelisable. In other words, the result of one pixel has no effect on the
result of any other pixel in the image. So it would be a simple matter of
dividing the pixels among a set number of threads. The best part of this is that
because each pixel is entirely independent, we can manage the entire system
without any thread locks. This is due to the fact that the scene is read-only
(marked const) and the threads will never write to the same pixel, so we don’t
need to guard the image itself.
So the new question is this: how do we divide the work among the threads? Well, there are several options we could try:
- We could assign a single pixel per thread. This would require some way of dispatching new pixels to the threads once they finish their work (essentially a work queue). This approach is simple but inefficient. The reason is the fact that each pixel won’t take the same amount of time. Therefore it is perfectly possible for threads to finish faster and therefore end up with nothing to do while other threads are locked up in the more complicated pixels. The overall goal of parallelising an algorithm is to ensure that CPU utilisation remains high, so let’s look at other options.
- We could divide the image into rows and have each thread do a given row. This is similar to the previous point, but with a larger unit of work. This approach would work well if we had a high number of cores (like the GPU), but this approach is still too similar to the previous one. It is going in the right direction though: since the CPU has a limited number of threads that (in general) will be smaller than the number of rows (or pixels), we need to divide the amount of work into larger chunks.
- We could divide the image into regions and assign each region to a thread. These regions (which we will call tiles) would help balance out the work in the threads, since it is easier to have regions that have a mix of both low and high work pixels. Note that it is still possible that we end up with tiles that are mostly empty, but we can reduce that by being a bit clever with the size and distribution of the tiles.
Option number 3 is the most common approach for parallelising ray tracers, so lets go with that. At runtime, we would end up with something like this:
| |
For the sake of simplicity, lets assume that the number of tiles is equal to the
number of threads. The thread render function would have our render function,
with the only difference being that instead of an image, it would take the tile,
which will tell it where to start and end on each of the two axes.
So, we have an idea of how we would solve it if we weren’t dealing with
constexpr functions, so now let’s figure out if we can somehow transfer this
over.
If we were to look at the CPU utilisation while we’re running our ray tracer, we would quickly realise that only a single core was being used. Looking through the compiler flags, we are always using the parallel flag, so why isn’t the compiler using multiple threads? Well the answer is simple: we are only ever generating a single executable, so the compiler only needs one thread to generate it… wait. We are generating a single executable, so we are using a single core, so it stands to reason that if we generated multiple executables, we would use multiple cores. But we don’t want multiple executables, so how do we do this… libraries!
Preparing the Tracer
The approach is the same as before: take the image and split it into tiles. The difference is that instead of assigning each thread a single tile, we’re going to be creating a static library per tile. Each library will be in charge of a specific region of the image, which it will then place into an array. All that the main executable needs to do is to loop through all the libraries and retrieve their tiles so they can be assembled into the final image. Perfect! But how do we generate the libraries?
Before we discuss how to generate the libraries themselves, lets modify the core
ray tracer to handle tiles instead of the full image. This involves a couple of
quick additions and changes. First, we need a tile structure, which will be
similar to the Image class. We end up with this:
| |
Notice that the class is functionally identical to the Image class, the only
major difference is that it takes in the size of the image and the tile. The
size of the image is important since it used to create the primary rays, while
the tile size is used to create and index into the container that holds the
pixel data.
Next, let’s modify the render function to accept the tile. The range of the
tile will be held by a simple struct:
| |
The new render function looks like this:
| |
The rest of the function remains the same, as the only changes that were needed
happened before the inner loop. Note the declaration of width and height
(this is why we needed the image dimensions) and the changes in the two loops to
use the size of the tile.
Now that we have everything ready to go, lets turn our attention to the CMake scripts we’ve been using.
Magic with CMake
So far, we’ve been using a single executable, so we could just pass in all of the files into it so they could be compiled. In order to create the new tile libraries, we’re going to have to split our code into 3 blocks:
- The core ray tracer: contains the bulk of the code, consisting of the shapes, BRDFs, materials, etc.
- The tile libraries: will contain the generator functions for each scene.
- The main executable: will be in charge of gathering all the tiles and merging into a single image. Note that this will have to be done at runtime.
With this in mind, our first order of business is to separate the core ray
tracing code into a separate library that will be called tracer. For the sake
of organisation, we’re going to be placing the files into their own folder
(src/tracer). After tweaking the CMake scripts a bit, we are now ready to
figure out how to generate the tile libraries.
CMake has a command called configre_file which takes in a template (generally
with a .in file extension) and creates a new file. The part that we’re
interested in here is that the template can contain special strings that will be
replaced when the new file gets created provided that the variable is defined in
the CMake script (or any scripts above it). So, we’re going to consolidate all
of the common code across the libraries into a single master template that they
will all ultimately be copied from. The template will have the strings
containing the per-library information that will be substituted when they are
created.
Since each library needs to define a single function to retrieve the tile, lets start with the header:
| |
When CMake reads this file, it will replace any string (or substring) that
begins and ends with @ with the corresponding value in the CMake script
itself. So, for the first tile, the get function would become get_tile_0.
The cpp template will look like this:
| |
Reading through this code, it may seem odd that we’re using the name of the tile as part of the function signature for the generators. After all, these functions are all defined within the cpp file and therefore aren’t visible outside of the current translation unit… right? Well, it turns out that if we were to compile and run our code without the tile name in the generator functions, we would always be invoking the generator function from the first tile! The reason why this happens is very simple: the functions all have the same names, so when the program gets linked, the linker only accepts the first version of the function (in this case the one corresponding to the first tile) and ignores the rest. In order to prevent this from happening, we need to have each function have a unique name, hence why we use the name of the tile.
We are now ready to modify the script to generate the libraries. The new script looks like this:
| |
There’s a lot going on here, so let’s go over it together. The math commands
are in charge of generating the width and height of the tiles based on the
number of tiles we want along each axes and the size of the image (which is
defined elsewhere). The reason why we subtract one from the number of tiles is
that loops in CMake run in the range $[s, e]$ where $s$ is the start and $e$ is
the end value, unlike most C++ loops which run in the range $[s, e)$. Since we
start counting at 0, we need to subtract one to ensure that we end up with the
correct number of tiles.
Next come the loops. File the fact that we’re setting the TILE_TARGET_LIST
variable for now, we’ll come back to it. The two loops iterate over each tile,
setting all of the values that the tiles need: the beginning, end, and dimension
along each axis. The name of the tile is constructed from the number along each
axis. After that we set the name of the files we are going to generate and then
we use configure_file to generate them using the templates we defined earlier.
Once that is done, we then create and configure the libraries themselves. This
is were we link against the main tracer library, as well as set all of the
required compiler flags. At the bottom of each loop we save the name of each
library that we create so we can then pass it up to the calling script.
The calling script looks like this:
| |
First, we define the size of the image. The reason why it’s defined here is
because the size is shared across two groups: the tiles and the main executable.
We then descend into the tracer subdirectory where the main tracer library is
defined and the tiles directory which contains the script we saw earlier.
At this point we have all of the tiles created and ready to go, but we still have one problem: how does the main executable know about the tiles? In particular, it needs to know the following:
- What headers should it include (and the names of those headers)?
- What are the functions that it must call to retrieve the tiles?
We have two options for dealing with this:
- We could change the type of library from static to dynamic and generate a header with the number of tiles per axis. The executable would then have to generate the list of all the dynamic libraries and load them on the fly. This option is unnecessarily complicated, since it involves loading/unloading dynamic libraries. While it is certainly possible, there must be a simpler way.
- Generate the entire executable with CMake. We can specify variables that contain the list of headers to include and the list of functions to loop over. All the executable would have to do is retrieve the tiles and combine them into the final image.
Since we have to generate something for both options, we might as well exploit
that and generate the entire executable ourselves. Notice that all of the
headers have the same pattern (basically just the tile name) and the get
functions are just a concatenation of get_ and the tile name. Therefore, to
generate the lists we need, all that we require are the names of the tiles…
sounds familiar doesn’t it? This is the reason why we saved the list of tiles
when we were generating them, because we can use them to construct the list of
headers and functions.
The for loop at the top just iterates over the list of tile names and generates
the patterns for the include lines and the function names. Once those are ready,
we have to clean up the lists generated by CMake. The first block of string
commands is in charge of removing the final , that would’ve been left in the
list of function names.
CMake by default creates lists of strings separated by ;. What we actually
want though is just a single string containing all of the includes and function
names (notice that the includes already carry the newline characters, so we
ensure that each header gets its own line). This is the purpose of the next
block of string commands: find and replace all ; characters with nothing.
The remaining part just generates the main cpp file and creates the executable linking it against the tiles. The template for the main cpp is the following:
| |
And… that’s it! All that is left is to specify the number of tiles we want and
off we go. If we set the number of tiles to be 2x2 and look at the CPU usage
we will see that we’re using more than one core (in my case, there are 4 cores
being used) which is exactly what we we’re looking for! We have successfully
parallelised our ray tracer.
Results
For the sake of completeness, let’s test the performance at the following tile
sizes: 2x2, 4x4, and 8x8 on a 600x400 image. The results are as follows:
| Scene | 1x1 Time | 2x2 Time | 4x4 Time | 8x8 Time |
|---|---|---|---|---|
| Just Background | 21m 6s | 16m 4s | 25s | 23s |
| Red Sphere | 11m 43s | 2m 8s | 32s | 29s |
| Shadows | 42m | 5m 3s | 23s | 1m 12s |
| Phong | 15m 33s | 4m 34s | 1m 26s | 1m 6s |
| Reflections | 17m 31s | 5m 36s | 1m 59s | 1m 18s |
We can push this by subdividing the image further. Just for fun, let’s try the final scene with 100 total tiles. With this setup, the renderer utilises 100% of the CPU and finishes in 1m 15s.
It may be tempting at this point to think about adding multisampling. After all,
we have parallelised the ray tracer, so adding several samples should be
doable… right?
Unfortunately the answer is still no. Adding 16 samples to the reflections scene
with 64 tiles causes the compiler to crash due to running out of heap space. In
fact, the amount of memory that is required to add multisampling with this setup
is enormous (way more than the 64 GB of RAM that I have available). While it
could be plausible to experiment by reducing the number of samples until it
allows the compiler to finish, the improvements would be negligible and the
performance hit just wouldn’t be worth it. Since each tile would need so much
memory, the CPU would very quickly start to thrash, which would in turn increase
the amount of time required to render the tile.
Showing Off
Now that we much faster way of ray tracing, let’s try a more complicated scene. Making some tweaks and increasing the reflection depth, we can end up with something like this:
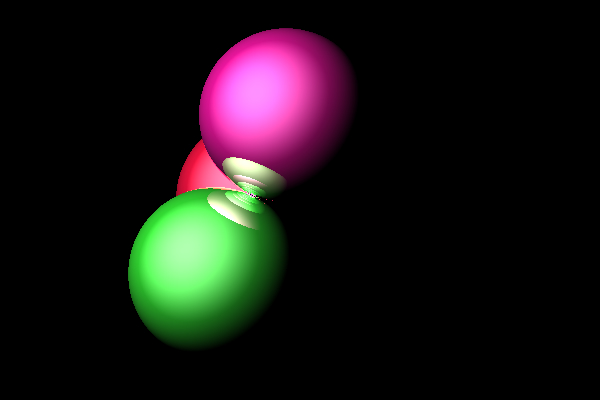
Which took 1m 3s to render.
Conclusion
So, what did we learn in this trip?
- We can “parallelise” the
constexprevaluations by splitting the code into different static libraries. This ensures that the compiler uses multiple cores to generate the required libraries. As with most parallelisation, there is an ideal balance between the number of cores in the system and the number of libraries for optimum performance.
With this, we have concluded our journey. Could this be pushed further? Definitely! The current architecture actually gives us a lot more flexibility with the amount of features we can implement, since we no longer have to wait over 30 minutes per render. That said, we are still limited very limited in some ways. In particular:
- Adding sampling increases the memory usage, which in turn limits the number of tiles we can have without the threads thrashing. This alone is the biggest limiting factor, since a low number of samples leads to a high amount of artefacts. The other consequence of this is that features such as ambient occlusion become either highly prohibitive or just impossible, since it relies very heavily on sampling. The same logic will apply with other sampling-heavy features.
So, if you’re interested, feel free to re-use the system we derived here for your own uses. If you do make something new, feel free to send me a link.
Well, that’s all for this series. Until we meet again, I bid you all a very fond farewell.
References
The following are the references used for this article in case you wish to read more about the discussed concepts.
Edits:
- 22/09/2024: Improved TOC and fixed some phrasing due to blog style changes.